Some Notes of Multimodality
Data Modalities
- Audio to Image: mel spectrograms
- Video to Image
- Text to Video: take a photo of text
- Data to Image: Chart
- Image to Text: Image to vector to tokens of text
- Audio to Text
Multimodal Tasks
- Vision Language Tasks
- Generation
- Image Generation (text-to-image synthesis)
- Model: Dall-E, Stable Diffusion, and Midjourney
- Text Generation
- Visual Question Answering (VQA)
- Image Generation (text-to-image synthesis)
- Vision-Language Understanding (VLU)
- Classification
- Text-Based Image Retireval (TBIR) (image search)
- Possible Approaches
- Generate caption and metadata for image
- given a text query, find images whose captions/metadata are closest to this text query
- Train a joint embedding space for both images and text
- Given a text query, generate an embedding for this query,
- and find all images whose embeddings are closest to this embedding.
- Generate caption and metadata for image
- Possible Approaches
- Generation
Fundamentals of Multimodal Trainging
-
Three Components
- Encoder for each data modality
- A way to align embeddings of different modality
- into the same multimodal embedding space
- (generative model only) A language model to generate text responses.
- CLIP: map data of different modalities, text and images, into a shared embedding space.
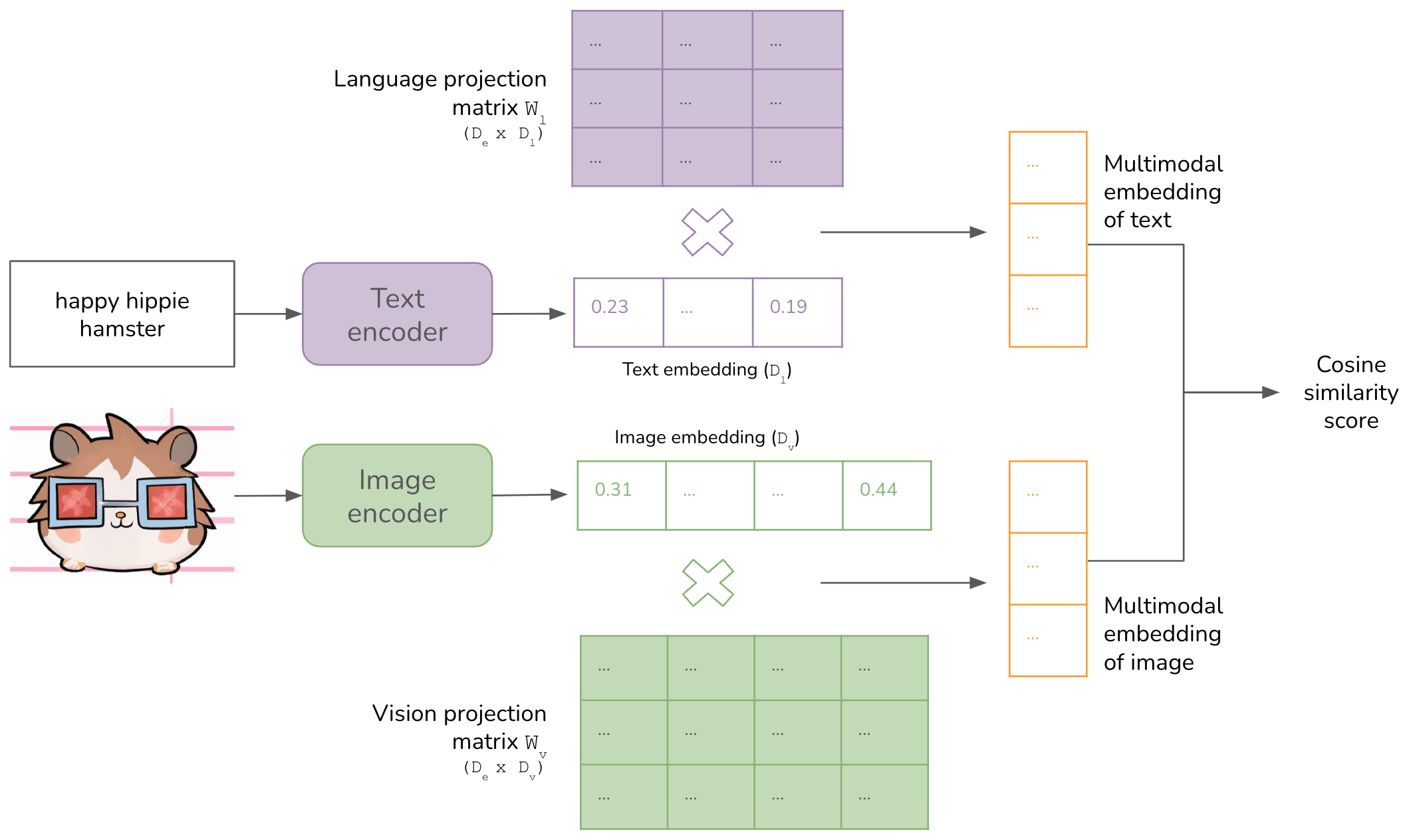
-
Flamingo: CLIP + a language model
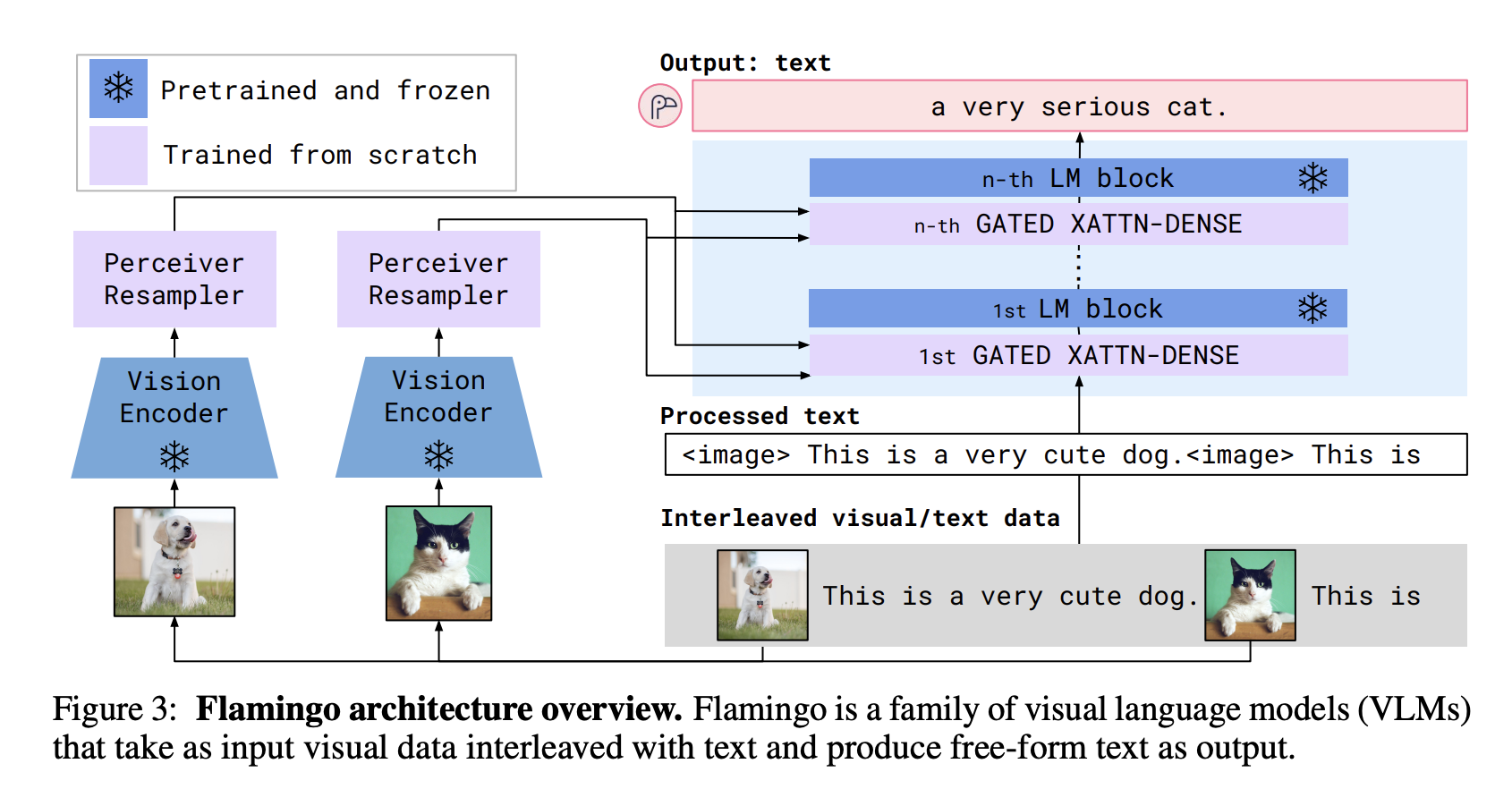
- Vision encoder: a CLIP-like model
- Language model: finetuned Chinchilla
- predicts the next text token based on both the preceding text and visual tokens
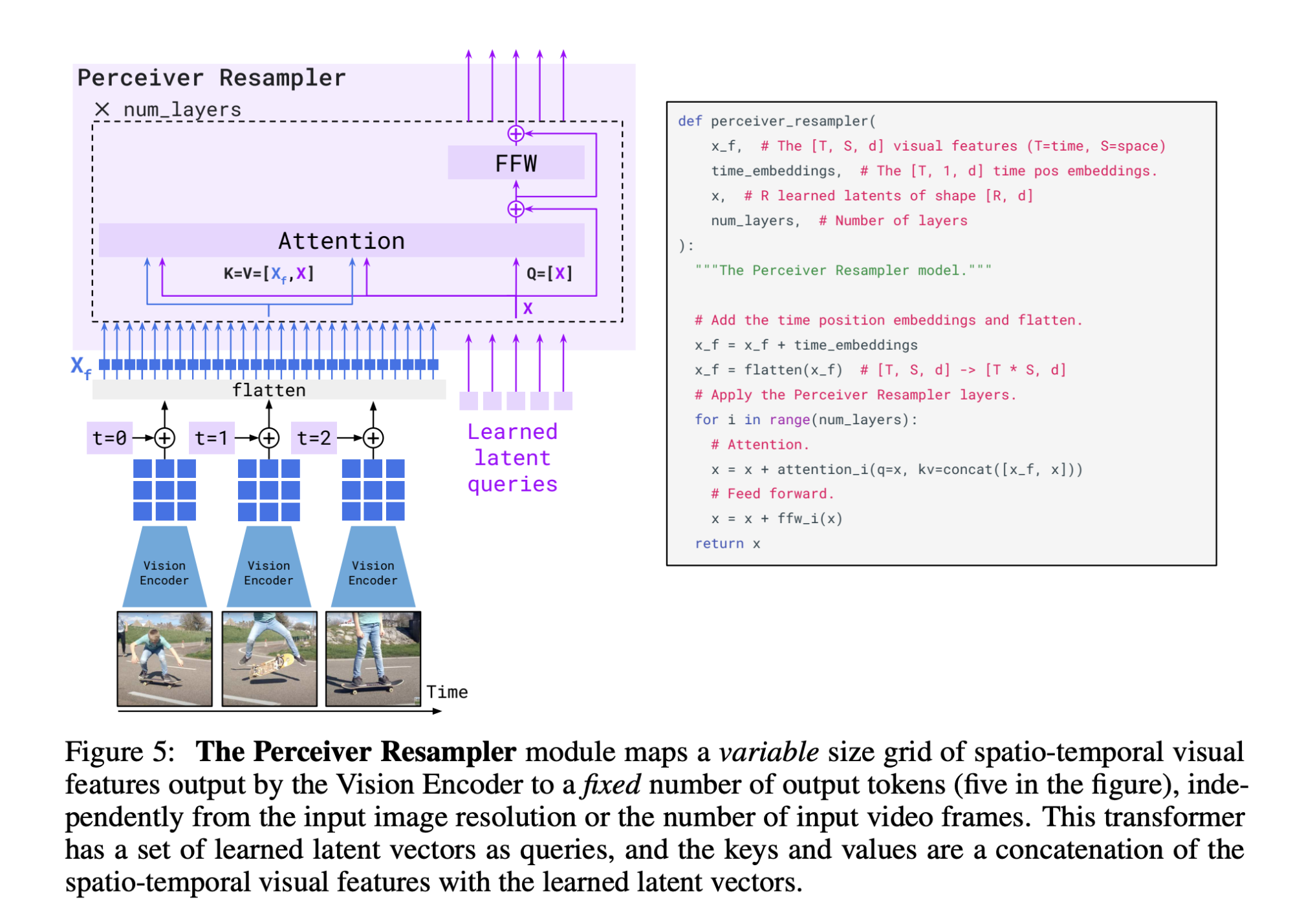
- Perceiver Resampler
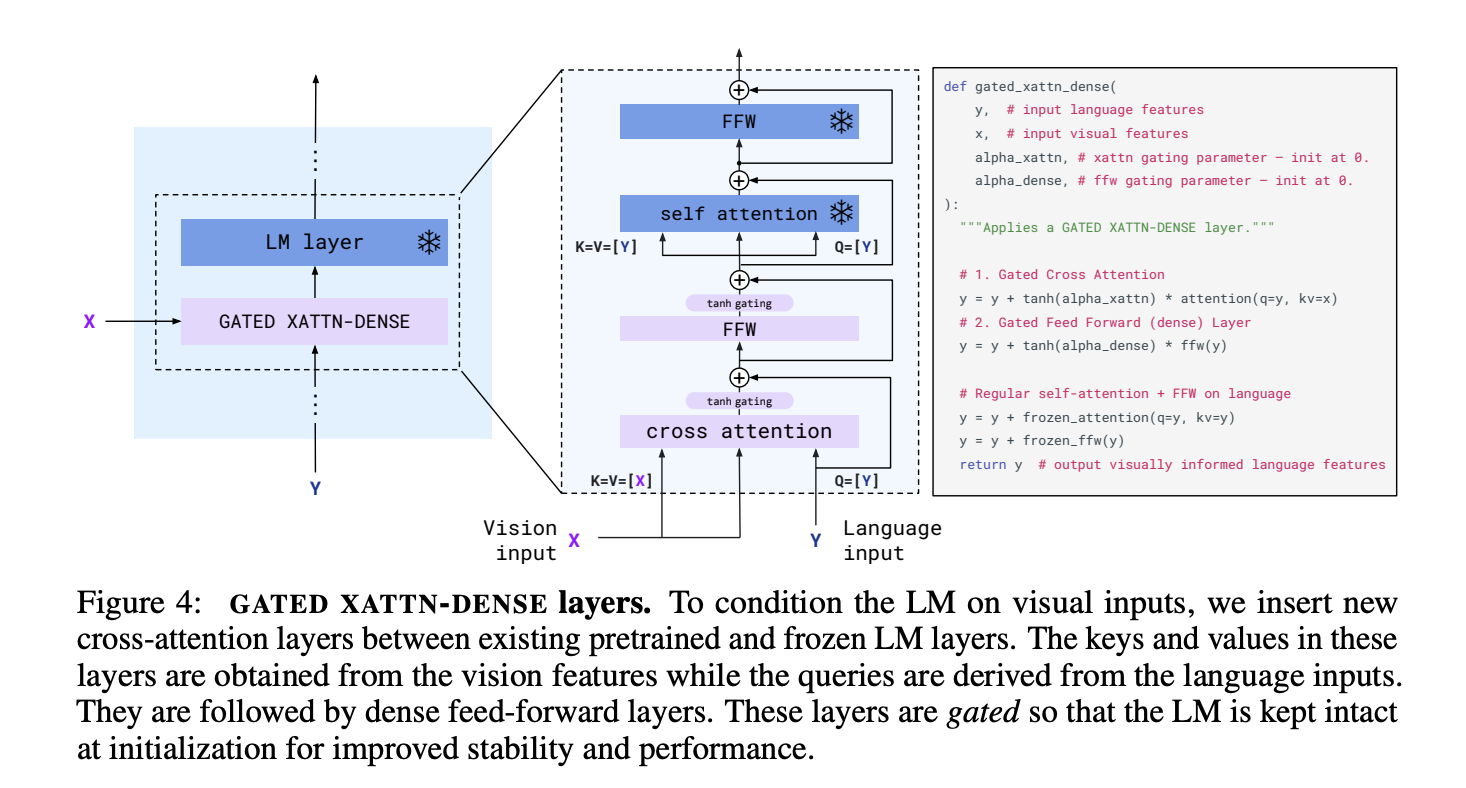
- GATED XATTN-DENSE layers
Reading List
- Incorporating more data modalities
- ULIP: Learning a Unified Representation of Language, Images, and Point Clouds for 3D Understanding (Xue et al., Dec 2022)
- ImageBind: One Embedding Space To Bind Them All (Girdhar et al., May 2023)
- NExT-GPT: Any-to-Any Multimodal Large Language Model (Wu et al., Sep 2023)
- Multimodal systems for instruction-following
- MultiInstruct: Improving Multi-Modal Zero-Shot Learning via Instruction Tuning (Xu et al., Dec 2022)
- LLaVA: Visual Instruction Tuning (Liu et al., Apr 28, 2023)
- InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning (Salesforce, May 11, 2023)
- LaVIN: Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models (Luo et al., May 24, 2023)
- Adapters for more efficient multimodal training